目次

X(旧Twitter)の消せないリポストを削除できるTweetXer
Xの古いポストにありがちですが、
画像のようにリポスト済みのときは緑色になるアイコンがグレーアウトして、リポストを取り消せなくなっていることがあります。
https://github.com/lucahammer/tweetXer
この手のリポストを削除したい場合はTweetXerと言うUserScriptが使えます。
正確にはリポストを含めた全てのポストが削除できるスクリプトで、以下の理由からかなりお手軽に動かせるのがメリット。
- APIキーが要らない
- パソコン版なら開発者ツールだけで動く
ポストを消したいだけなのにAPIを動かせる環境を用意するのは面倒ですからね。
スマホからもTampermonkeyを使えば動かせますが、以下の理由からパソコンで作業する方がオススメです。
- ファイルサイズの大きいXの全データをDLする必要がある
- 特定のポストを削除したい場合はtweet-headers.jsを編集する必要がある
『X リポスト 取り消せない』とかで検索すると的外れな記事ばかりが引っかかるので記事にしました。
使い方
公式や動画の説明があるので簡単にまとめると
- Xから全データをダウンロードする
『設定』→『アカウント』→『データのアーカイブをダウンロード』
- ダウンロードしたZIPアーカイブを解凍する
-
TweetXerに『Select your tweet-headers.js from your Twitter Data Export to start the deletion of all your Tweets.』と表示されるのを待つ
- 解凍したアーカイブの中にあるtweet-headers.jsをTweetXerの『参照』から読み込ませる
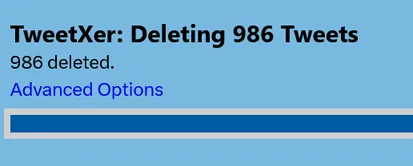
- 全ポストが削除される
Tampermonkey版のTweetXerは有効化していると強制的にホーム画面に移動しますが、削除に必要な情報を取得するためなので仕様です。
古いリポストを削除した図。
実際には全ポストを削除したいと言う人はあまりいないと思うので、tweet-headers.jsを編集することになると思います。
JSONファイルを編集するので、特定のポストやリポストを削除したい場合は結構面倒。
少数なら手動でやってもいいですが、数が多い場合はやはりパソコン上でPythonなどを使うことになるかと。
2025年7月現在、最新版TweetXerは動かない
Doesn't work, bar doesn't move and not tweets deleted · Issue #38 · lucahammer/tweetXer
上記Issueが上がっています。
過去のバージョンは動くので修正されるまではこちらを使いましょう。
どうあっても動作しないことがある
全く同じ操作手順を踏んでも動作しないことがあります。
と言うよりも動作する確率は1/5くらい?
Xの制限なのか分かりませんが、パソコンの開発者ツールで見るとHTTPステーラス400が返ってきていることがほとんど。
珍しいことではないので間隔をあけて何回か試しましょう。
削除したいポストのIDだけを書いたファイルからtweet-headers.jsを作るPythonスクリプト
ほぼパソコンなしでは実行できないので興味のある人だけ読んでいただければ。
XのポストのURLは以下のような形式です。
https://x.com/[username]/status/[1945123456789]
この数字部分だけを書いたファイルを用意するとtweet-headers.jsを作成してくれるPythonスクリプトを用意しました。
- 削除したいポストの末尾の数字だけを書いたファイルをdelete-ids.txtと言う名前で用意
例:
1945123456789
1946123456789
1947123456789
...
- tweet-headers.jsと同階層に以下のPythonファイルとdelete-ids.txtを置く
- python ./delete.pyを実行
上記操作だけでポストIDからtweet-headers.jsをfiltered-headers.jsと言う名前で書き出すので、それをTweetXerに読み込ませればOK。
import json
import re
from pathlib import Path
# ファイルから tweet_id を抽出(JSONと数字行の両方対応)
def load_ids_from_mixed_json(file_path):
id_set = set()
with open(file_path, encoding="utf-8") as f:
for line in f:
line = line.strip()
# 行が {"tweet_id": "123456789"} のようなJSON含む場合
match = re.search(r'"tweet_id"s*:s*"(d+)"', line)
if match:
id_set.add(match.group(1))
# 行が数値だけの場合
elif re.fullmatch(r"d{5,}", line): # ある程度の桁数制限も可能
id_set.add(line)
return id_set
# JSファイルから中身だけ抽出
def extract_json_array(file_path):
with open(file_path, encoding="utf-8") as f:
js = f.read()
match = re.search(r'=s*([s*{.*}s*]);?s*$', js, re.DOTALL)
if not match:
raise ValueError(f"Cannot parse JSON array from: {file_path}")
return json.loads(match.group(1))
# データ読み込み
def load_tweet_headers(path):
return {item["tweet"]["tweet_id"]: item["tweet"] for item in extract_json_array(path)}
# id_set に該当するtweetだけを抽出
def filter_headers(headers, id_set):
return [{"tweet": tweet} for id_, tweet in headers.items() if id_ in id_set]
# 実行
def main():
input_path = Path("delete-ids.txt")
headers_path = Path("tweet-headers.js")
output_path = Path("filtered-headers.js")
id_set = load_ids_from_mixed_json(input_path)
headers = load_tweet_headers(headers_path)
filtered = filter_headers(headers, id_set)
# 先頭に window.YTD.tweet_headers.part0 = を追加
with open(output_path, "w", encoding="utf-8") as f:
f.write("window.YTD.tweet_headers.part0 = ")
json.dump(filtered, f, ensure_ascii=False, indent=2)
print(f"{len(filtered)} 件の tweet を抽出しました。")
if __name__ == "__main__":
main()